Modern History for Text Summarization
1. The Heat Change of Summarization Research (Updating...)
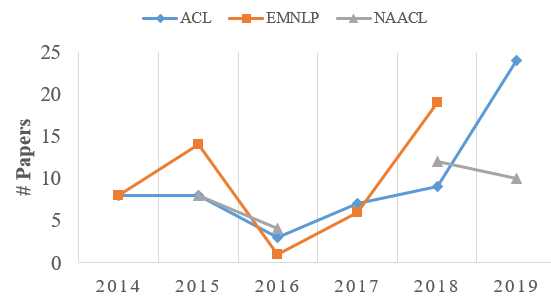
Fig.1 The number of accepted papers from ACL, EMNLP, NAACL over the past six years.
As shown in Fig.1, we can observe the influence of deep neural networks on the development of summarization. And next we will make brief descriptions of some key turning points:
- The neural networks are brought into NLP by [1] in 2011 with a unified framework (not the first one but the most complete one). After that (from 2011~2013), there are some related researchers who mainly focused on the word representation learning problem, discussing how to speed up the training process of the language model. The deep neural networks have been officially applied to mainstream NLP tasks at around 2014, and the tasks to be early investigated are relatively simple, mainly concentrating on text representation learning and classification, such as CNN [2, 3] ,RNN [4 ,5] .
- 2014: When we put our attention on text summarization, we found that for those papers accepted by EMNLP/ACL2014 (see below “Knowledge base of Summarization Papers”), there are few about neural networks. Why? Let’s think about it. At that time, we still don’t know what structures of the networks can be used for sentence encoding. For example, researchers haven’t known how to utilize CNN to better model text, not to mention the more complex task, text summarization.
-
2014->2015: in 2014, there are some major events in NLP community that seem worth remembering now:
a) The proposal of seq2seq learning framework based on LSTM [6](At that time, no one believed seq2seq could work or LSTM could work)
b) Attention mechanism [7]
These ground-breaking networks are first applied to machine translation. So, we can guess what would happen next: just looking for a nail with a hammer. Now that the model has been ready, there is no reason not to try other tasks. Therefore, we have seen several papers in EMNLP2015 that use neural networks for summarization tasks. Among these papers, Rusn’s work [8] has been widely remembered, since that ‘s the first one to use the hammer “attention”. (Of course, it’s not that easy). In this year, there was another awesome work [9] , which proposed a new dataset for neural abstractive summarization. - 2015->2016: During this year, the development of the summarization filed seems to have begun to plateau. The possible reason is that there is no updated technical support in terms of model, data, or training methods. Here, Chen et al. 's work [10] has played an important role in the development of this field, by formulating extraction summarization task into neural sequence labeling problems.
- 2016->2017: this year can be said to be the "eve" of the outbreak of abstract field research. Specifically manifested in: a) Training methods: reinforcement learning and adversarial learning have begun to land in NLP, which make it possible to consider more loss functions for summarization tasks; b) The introduction of CNN/DM datasets (with some baselines that are not too high) significantly promotes the development of this field; c) model structures: the proposal of new mechanisms such as copy [11] /coverage [12] .
- 2017->2018: thanks to several important preparations (model structure, datasets and training methods) in 2017, the development of summarization field has entered a golden period in this year, especially in the EMNLP2018, nearly 20 papers have been accepted.
- 2019: Based on the current acceptance of NAACL and ACL, we can conjecture that this year is a summarization year, in which the number of related papers in ACL is more than 20, and it can be expected that EMNLP will not be less. One of the important reasons here can be attributed to the development of unsupervised pre-training model (ELMo, BERT).
- From 2016 to 2019 years, the task continues to get hot. The new models are being proposed and each paper claims that they have achieved a state-of-the-art performance. So, what are the key points that drive summary task performance? The paper “Searching for Effective Neural Extractive Summarization: What Works and What's Next” explores this and provides a set of ideas for NLP-oriented neural network analysis.
2. Data Warehouse
Single-document Summarization
-
Gigaword:[paper] [data]
The dataset is organized by Rush for abstractive summarization, which contains many spurious headline-article pairs. There are 3.8M training, 189k development and 1951 test samples. -
LCSTS:[paper] [data]
A large corpus of Chinese short text summarization dataset constructed from the Chinese microblogging website Sina Weibo. -
CNN/DM:[paper] [data]
The dataset is re-organized by Nallapati, covering 286,817 training pairs, 13,368 validation pairs and 11,487 test pairs. -
Newsroom:[paper] [data]
It’s a summarization dataset of 1.3 million articles and summaries written by authors and editors in newsrooms of 38 major news publications. -
Newsroom-processed (ACL2019):[paper] [data]
The original Newsroom dataset is pre-processed and repurposed for cross-domain evaluation. -
Xsum:[paper] [data]
The dataset is collected a real-world, large scale dataset for this task by harvesting online articles from the British Broadcasting Corporation, which does not favor extractive strategies and calls for an abstractive modeling approach. -
arXiv:[paper] [data]
Scientific papers which are an example of long-form structured document types PubMed:scientific papers which are an example of long-form structured document types -
PubMed:[paper] [data]
Scientific papers which are an example of long-form structured document types. -
RottenTomatoes:[paper] [data]
It is a movie review website that aggregates both professional critics and user-generated reviews -
Reddit TIFU:[paper] [data]
The dataset could less suffer from some biases that key sentences usually locate at the beginning of the text and favorable summary candidates are already inside the text in similar forms. -
BIGPATENT (ACL2019):[paper] [data]
It consists of 1.3 million records of U.S. patent documents along with human written abstractive summaries.
Multi-document Summarization
-
DUC:[paper] [data]
NIST launched a new text summarization evaluation effort, called DUC. -
WikiSum:[paper] [data]
The input is comprised of a Wikipedia topic (title of article) and a collection of non-Wikipedia reference documents, and the target is the Wikipedia article text. -
ScisummNet (Yale University; AAAI19):[paper] [data]
It contains 1,000 examples of papers, citation information and human summaries, is orders of magnitude larger than prior datasets. -
Multi-News (Yale University; ACL2019):[paper] [data]
A multi-document summarization dataset in the news domain.
Multi-modal Summarization
-
MMS:[paper] [data]
The dataset provides an asynchronous (i.e., there is no given description for images and no subtitle for videos) collection of multi-modal information about a specific news topics, including multiple documents, images, and videos, to generate a fixed length textual summary. -
MSMO:[paper] [data]
The dataset provides a testbed for Multimodal Summarization with Multimodal Output, constructed from Daily Mail website. -
How2:[NeurIPS18] [ACL19][data]
The corpus consists of around 80,000 instructional videos (about 2,000 hours) with associated English sub-titles and summaries.
New tasks for Summarization
-
Idebate:[paper] [data]
It is a Wikipedia-style website for gathering pro and con arguments on controversial issues. -
Debatepedia:[paper] [data]
The dataset is created from Debatepedia an encyclopedia of pro and con arguments and quotes on critical debate topics. -
Funcom:[paper] [data]
It is a collection of ~2.1 million Java methods and their associated Javadoc comments. -
TALKSUMM (ACL2019):[paper] [data]
It contains 1716 summaries for papers from several computer science conferences based on the video of talk. -
Multi-Aspect CNN/DM (ACL2019):[paper] [data]
An aspect-based summarization dataset.
3. Typical Research Problems
We have summarized and classified the research problems of existing work based on more than 100 papers in the last six years, to share them in the hope that more beginners can learn the most core things in this field more quickly.Generating way
-
Extractive Summarization
a) The choices of encoder
b) The choices of decoder
c) How to model the semantic relationship between sentences
-
Abstractive Summarization
a) OOV
b) How to improve the abstractiveness of existing systems
-
Compressive Summarization
a) How to define a valid scoring function and filter different semantic units based on it
The number of source documents
-
Single-document
-
Multi-document
New Datasets and Evaluations
-
Evaluation
-
New datasets
Learning Methods
-
Unsupervised
-
Supervised
Multi-X
-
Multi-lingual
-
Multi-modal
Defition of new tasks
-
Summary of programming language
-
Argument mining
-
Query-based summary
4. Active Research Groups
China
-
The Language Computing and Web Mining Group lead by Xiaojun Wan
-
The Social Media Mining Group lead by Wenjie Li
-
The PKU Summarization Group lead by Li Sujian, Rui Yan
North America & Europe
-
Columbia NLP Group lead by Kathleen McKeown
-
Yale NLP Group lead by Dragomir Radev
-
Harvard NLP lead by Alexander Rush
-
Edinburgh Group lead by Mirella Lapata
-
UT Austin NLP Group lead by Greg Durrett
-
McGill NLP Group lead by Jackie Chi Kit Cheung
-
UNC NLP Group lead by Mohit Bansal
-
Northeastern NLP group lead by Lu Wang
-
University of Central Florida NLP group lead by Fei Liu
-
Tokyo Institute of Technology Summarization group lead by Hiroya Takamura
Company
-
Microsoft Research Asia Summarization Group: Chin-Yew Lin, Furu Wei
-
Tencent AI Summarization Group: Piji Li
-
Google Cloud Summarization Group: Peter J. Liu
-
Salesforce NLP Research: Richard Socher
- More than 140 papers accepted from ACL, EMNLP and NAACL. (from 2014 to 2019) were collected. "TBC." means a paper that has not been published or has not been annotated by myself.
- Each column in the table can be customized in ascending/descending order; Keyword retrieval is also possible.
- "Summary": a Summary of the most important content.
- "Dataset": represents the Dataset used in corresponding paper.
- "Generating Way:" the way to generate summary: extractive/abstractive/compressive
- "Super/Unsuper.": supervised or unsupervised learning
- "Single/Multi.": Single or Multi document summary generation
- The above statistics are inevitably missing something, welcome everyone to add and promptly inform.(email:stefanpengfei@gmail.com)
- The page will be updated timely and permanently.
- Later, we will introduce other "modern history": sequence tagging, semantic matching, representation learning and multi-task learning ...
4. Knowledge Base for Summarization Papers
Instructions:
5. Postscript