文本摘要的“近代史”
1. 摘要研究的热度变化 (更新中...)
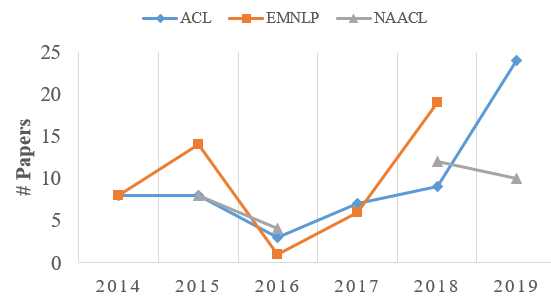
Fig.1 近六年NLP三大顶会(ACL, EMNLP and NAACL)中摘要相关论文录取情况
从图1,我们可以看到神经网络对摘要任务发展的影响,下面我来尝试解释下图里的几个关键结点:
- 深度神经网络早在2011就被Collobert等人[1]以统一的架构带入到NLP,此后在2011~2013这几年间有一些相关的研究,但主要集中在基于语言模型优化的词表示学习问题。它正式被应用到各大任务是在2014年左右,并且最先被调研的任务都是比较简单的,主要关注于文本表示及分类的问题。 比如CNN [2, 3] ,RNN [4 ,5] 。
- 2014:当我们把目光放到摘要这个任务上,我们发现,在2014年,EMNLP/ACL录用的文章里(见如下"摘要文章知识库"),几乎很少涉及到神经网络的文章。 为什么呢?我们可以想想,在那个时代,我们都还不清楚用什么结构的网络去编码句子,不知道怎么使用CNN去建模文本,连简单的文本分类都不清楚怎么引入合适的深度神经网络,更别说复杂度更高的文本摘要任务了。
-
2014->2015:2014年,“深度学习圈”发生了在现在看来值得记住的大事,比如:
a) 基于LSTM的seq2seq框架的提出 [6] (那个时候很少人会想到seq2seq会work,LSTM会work),
b) attention机制的提出 [7],
这些具有突破性结构的网络最先被应用到机器翻译任务上。 所以下面我们也能猜到会发生什么了:拿着锤子去找钉子呗。既然模型已经ready,没有道理不去试水下其它的任务。所以我们看到在2015年EMNLP里已经出现多篇使用神经网络去解决摘要任务的工作。其中比较能让大家记住的是Rusn这篇工作 [8] ,而记住的原因就是,它最早使用了attention这个锤子(当然,这看起来容易,但很多时候也没那么简单,比如那个时候国内很多机构都没有GPU)。这一年还有个工作 [9] ,是诺亚实验室和哈工大合作的一篇做数据集的文章,那个时候李航和吕东东老师的研究组做出了很多引领性的工作(仍然记得第一次见到吕老师,他一直给我强调趁早入手GPU的重要性) - 2015->2016:在这一年里,摘要领域的发展似乎遇到了一个瓶颈。可能的原因在于:无论从模型,数据,还是训练方式上,都没有更新的技术支持。这里Chen等人的工作 [10] 对这个领域的发展起到了一些作用,比较形式化地把抽取式摘要转化成序列标注问题,并且使用神经网络处理。
-
2016->2017:这一年可以说是摘要领域研究爆发的“前夜”。具体表现在:
a) 训练方式上:强化学习、对抗学习开始登陆NLP,使得摘要任务有了可以考虑更多损失函数的可能;
b) CNN/DM的数据集的提出(搭配一些不太高的baselines),大大推动这个领域的发展;
c) 模型结构上:copy [11] /coverage [12] 等新机制的提出。
- 2017->2018:正是有了17年几个重要的铺垫(模型结构、数据集以及训练方式),这一年摘要领域的发展迎来黄金期,尤其是2018年的EMNLP,录用了将近20余篇。
- 2019:从目前NAACL和ACL的录用数来看,今年又是摘要大年,其中ACL中摘要相关的论文更是破纪录的超过20,可以预期的是EMNLP也不会少。这里其中一个重要原因也可以从数据角度分析,无监督预训练模型(ELMo, BERT)的发展。
- 从16年~19年,摘要任务持续走热,提出的新模型也是不胜枚举。每篇文章都提供了一个可以“超过前人模型”的方法,那么左右摘要任务性能的关键点到底在哪呢?ACL19这篇文章 Searching for Effective Neural Extractive Summarization: What Works and What’s Next 对此做了探讨,并提供了一套面向NLP任务的神经网络分析的思路。
2. 数据仓库
单文档摘要
-
Gigaword:[paper] [data]
The dataset is organized by Rush for abstractive summarization, which contains many spurious headline-article pairs. There are 3.8M training, 189k development and 1951 test samples. -
LCSTS:[paper] [data]
A large corpus of Chinese short text summarization dataset constructed from the Chinese microblogging website Sina Weibo. -
CNN/DM:[paper] [data]
The dataset is re-organized by Nallapati, covering 286,817 training pairs, 13,368 validation pairs and 11,487 test pairs. -
Newsroom:[paper] [data]
It’s a summarization dataset of 1.3 million articles and summaries written by authors and editors in newsrooms of 38 major news publications. -
Newsroom-processed (ACL2019):[paper] [data]
The original Newsroom dataset is pre-processed and repurposed for cross-domain evaluation. -
Xsum:[paper] [data]
The dataset is collected a real-world, large scale dataset for this task by harvesting online articles from the British Broadcasting Corporation, which does not favor extractive strategies and calls for an abstractive modeling approach. -
arXiv:[paper] [data]
Scientific papers which are an example of long-form structured document types PubMed:scientific papers which are an example of long-form structured document types -
PubMed:[paper] [data]
Scientific papers which are an example of long-form structured document types. -
RottenTomatoes:[paper] [data]
It is a movie review website that aggregates both professional critics and user-generated reviews -
Reddit TIFU:[paper] [data]
The dataset could less suffer from some biases that key sentences usually locate at the beginning of the text and favorable summary candidates are already inside the text in similar forms. -
BIGPATENT (ACL2019):[paper] [data]
It consists of 1.3 million records of U.S. patent documents along with human written abstractive summaries.
多文档摘要
-
DUC:[paper] [data]
NIST launched a new text summarization evaluation effort, called DUC. -
WikiSum:[paper] [data]
The input is comprised of a Wikipedia topic (title of article) and a collection of non-Wikipedia reference documents, and the target is the Wikipedia article text. -
ScisummNet (Yale University; AAAI19):[paper] [data]
It contains 1,000 examples of papers, citation information and human summaries, is orders of magnitude larger than prior datasets. -
Multi-News (Yale University; ACL2019):[paper] [data]
A multi-document summarization dataset in the news domain.
多模态摘要
-
MMS:[paper] [data]
The dataset provides an asynchronous (i.e., there is no given description for images and no subtitle for videos) collection of multi-modal information about a specific news topics, including multiple documents, images, and videos, to generate a fixed length textual summary. -
MSMO:[paper] [data]
The dataset provides a testbed for Multimodal Summarization with Multimodal Output, constructed from Daily Mail website. -
How2:[NeurIPS18] [ACL19][data]
The corpus consists of around 80,000 instructional videos (about 2,000 hours) with associated English sub-titles and summaries.
新的摘要任务
-
Idebate:[paper] [data]
It is a Wikipedia-style website for gathering pro and con arguments on controversial issues. -
Debatepedia:[paper] [data]
The dataset is created from Debatepedia an encyclopedia of pro and con arguments and quotes on critical debate topics. -
Funcom:[paper] [data]
It is a collection of ~2.1 million Java methods and their associated Javadoc comments. -
TALKSUMM (ACL2019):[paper] [data]
It contains 1716 summaries for papers from several computer science conferences based on the video of talk. -
Multi-Aspect CNN/DM (ACL2019):[paper] [data]
An aspect-based summarization dataset.
3. 研究问题
我们对最近6年的100多篇论文进行了研究问题的总结和归类,分享的目的是希望更多初学者可以更快地了解这个领域最核心的东西。产生方式
-
抽取式摘要(Extractive)
a) 句子编码器(encoder)的选择?
b) 如何建模句间的语义关系?
c) 解码器(decoder)的选择?
-
抽象式摘要(Abstractive)
a) 未登录词处理?
b) 如何增加生成文本的抽象性?
-
压缩式摘要(Compressive)
a) 如何定义有效的打分函数并据此作出不同语义单元的筛选?
文档源个数
-
单文档摘要(Single-document)
-
多文档摘要(Multi-document)
数据集、评估
-
新评估方式(Evaluation)
-
新数据集(New datasets)
学习方式
-
无监督学习(Unsupervised)
-
有监督学习(Supervised)
多语言/模态
-
多语言学习(Multi-lingual)
-
多模态学习(Multi-modal)
摘要新任务定义
-
编程语言摘要
-
论点挖掘
-
基于查询的摘要
4. 活跃研究小组
国内高校
-
The Language Computing and Web Mining Group lead by Xiaojun Wan
-
The Social Media Mining Group lead by Wenjie Li
-
The PKU Summarization Group lead by Li Sujian, Rui Yan
国外高校
-
Columbia NLP Group lead by Kathleen McKeown
-
Yale NLP Group lead by Dragomir Radev
-
Harvard NLP lead by Alexander Rush
-
Edinburgh Group lead by Mirella Lapata
-
UT Austin NLP Group lead by Greg Durrett
-
McGill NLP Group lead by Jackie Chi Kit Cheung
-
UNC NLP Group lead by Mohit Bansal
-
Northeastern NLP group lead by Lu Wang
-
University of Central Florida NLP group lead by Fei Liu
-
Tokyo Institute of Technology Summarization group lead by Hiroya Takamura
公司
-
Microsoft Research Asia Summarization Group: Chin-Yew Lin, Furu Wei
-
Tencent AI Summarization Group: Piji Li
-
Google Cloud Summarization Group: Peter J. Liu
-
Salesforce NLP Research: Richard Socher
- 收集了从2014~2019三大会议(ACL/EMNLP/NAACL)被录用的140多篇论文。 “TBC.”表示没有放出或者还没有完成阅读统计的论文。
- 表格中每一列都可以自定义按照升序/降序排列;并且也可以进行关键词检索。
- "Summary": 表示对最核心内容的概括。
- "Dataset": 表示文章中使用到的数据集
- "Generating Way": 表示产生摘要的方式:extractive/abstractive/compressive
- "Super/Unsuper.": 有监督/无监督学习的摘要生成
- "Single/Multi.": 单文档/多文档的摘要生成
- 以上统计难免挂一漏万,欢迎大家随时补充并及时告知。(email:stefanpengfei@gmail.com)
- 这个摘要的近代史页面将会永久动态更新。
- 后面会陆续推出序列标注、语义匹配、表示学习、多任务学习等“近代史”介绍。
4. 摘要文章知识库
使用说明:
5. 说明