Rethinking Generalization of Neural Models: A Named Entity Recognition Case Study
Jinlan Fu*, Pengfei Liu*, Qi Zhang, Xuanjing Huang
Do you have these questions?
- As a NER researcher, don't you wonder which problems (bottleneck) hold back the progress of this task?
- Does this excellent performance (with BERT) imply a perfect generalization model, or are there still some limitations?
- Do we have a perfect dataset or perfect evaluation methodology?
- How to quantify the interesting phenonmen in the task of NER?
- What's the next or the right direction for the NER?
We help you to find the answer!
In this paper, we take the NER task as a testbed to analyze the generalization behavior of existing models from different perspectives and characterize the differences of their generalization abilities through the lens of our proposed measures, which guides us to better design models and training methods. Experiments with in-depth analyses diagnose the bottleneck of existing neural NER models in terms of breakdown performance analysis, annotation errors, dataset bias, and category relationships, which suggest directions for improvement. We have released the datasets: (\textit{ReCoNLL}, \textit{PLONER}) for the future research.
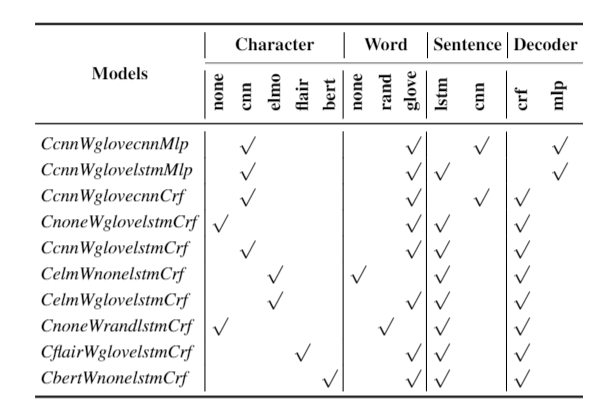
Fig. Neural NER systems with different architectures andpre-trained knowledge, which we studied in this paper.
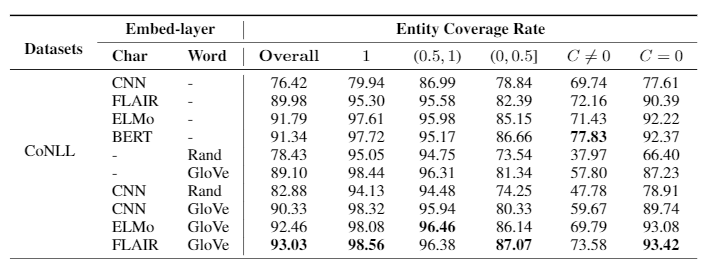
Fig. The breakdown performance on CoNLL.
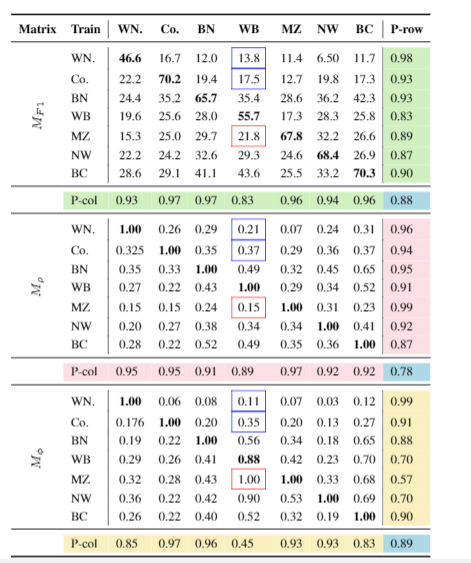
Fig. Experimental design for understanding cross-dataset generalization.
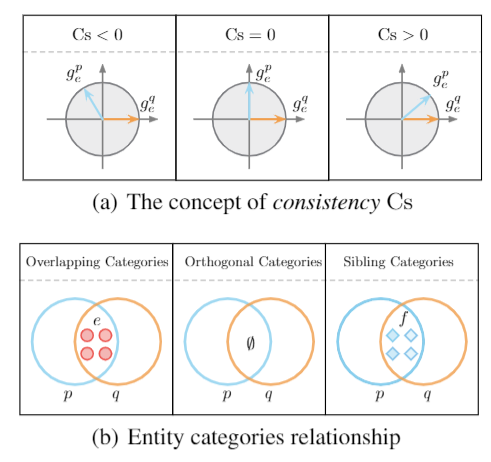
Fig. Probing Inter-category Relationships via Consistency.
Our Paper
Notable Conclusions
- The fine-grained evaluation based on our proposed measure reveals that the performance of existing models (including the state-of-the-art model) heavily influenced by the degree to which test entities have been seen in training set \textit{with the same label}.
- The proposed measure enables us to detect human annotation errors, which cover the actual generalization ability of the existing model. We observe that once these errors are fixed, previous models can achieve new state-of-the-art results, $93.78$ F1-score on CoNLL2003.
- We introduce two measures to characterize the data bias and the cross-dataset generalization experiment shows that the performance of NER systems is influenced not only by whether the test entity has been seen in the training set but also by whether the context of the test entity has been observed.
- Providing more training samples is not a guarantee of better results. A targeted increase in training samples will make it more profitable.
- The relationship between entity categories influences the difficulty of model learning, which leads to some hard test samples that are difficult to solve using common learning methods.
Dataset
- PLONER (Person, Location, Organization NER) is purposed to evaluate the cross-domain generalization. We pick the samples which contain at least one of three entity type (Person, Location, Organization) from representative datasets, such as WNUT16, CoNLL03, OntoNotes 5.0.
- ReCoNLL is revised on CoNLL-2003. We manually fixed errors with the instruction of the measure ECR (entity coverage ratio) proposed by the work. Specifically, we corrected 65 sentences in the test set and 14 sentences in the training set.
Bonus: a NER Paper Searching System