Neural Representation Learning for Natural Language Processing
Pengfei Liu
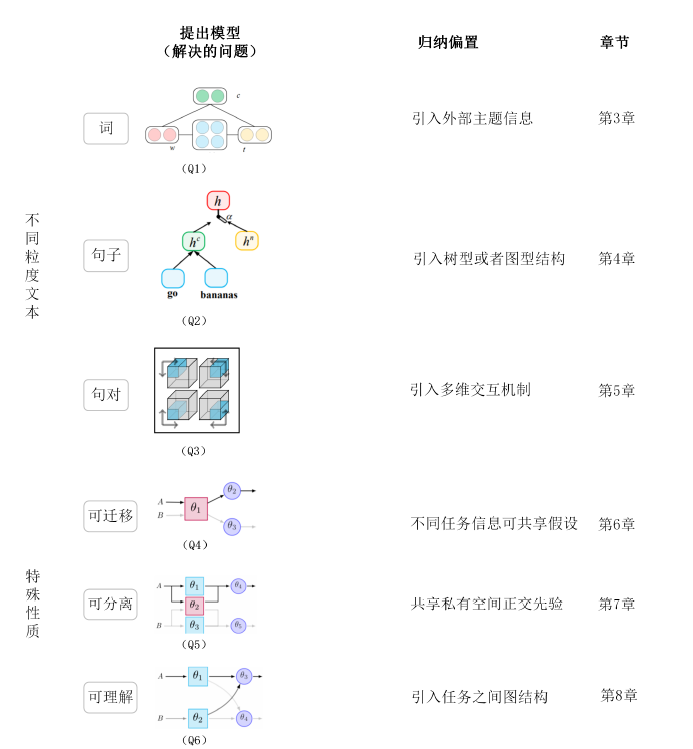
Fig. Framework of my thesis.
Abstract
Representation learning refers to the transformation of input data into a form suitable for machine learning. Usually, the performance of machine learning depends on the choice of data representation. A good representation can make the model understand the input data better. In recent years, the rise of neural networks has enabled us to automatically extract features from input data, which has greatly promoted the development of representation learning and brought us various possibilities . Generally speaking, the research on representation learning can be divided into supervised and unsupervised learning; text representation, image representation and speech representation; shared representation and private representation from the perspective of sharing independence. In Natural Language Processing, the use of deep learning technology (deep neural networks) for text representation has become a valuable research direction. In this thesis, our study makes a feasible step towards the answers of the following questions: 1) \textbf{For different granularities of texts (words, sentences, sentence pairs), how to design a reasonable inductive bias so that the model can learn the suitable representation for downstream tasks? } The arrival of deep learning leads to the shift from feature engineering to present architecture engineering. For text representation learning, the most fundamental problem is to find the appropriate structure bias, so as to better encode the input text signal. In this thesis, we explored the representation learning of different granularities of text spans, in order to find a more suitable structure bias for the specific task. 2) \textbf{How can we only transfer knowledge we need?} In order to achieve this goal, the knowledge learned should be \textit{transferable} first, since what we really want to achieve is to transfer whatever knowledge we need. Towards this end, we also need to carry out \textit{interpretable analysis} on knowledge, and then \textit{disentangle} them to take out the part which we really need for the task we care about. With the above two questions in mind, this thesis conducts a progressive discussion through two parts and nine chapters. 表示学习(representation learning),又称表征学习,是指将输入数据转化成适用于机器学习形式的过程。通常地,机器学习的性能依赖于对数据表示的选择,一个好的表示可以使得模型对输入数据进行更好的理解。 近年来,神经网络的兴起,使得我们可以自动地对输入数据进行特征抽取。这极大推动了表示学习的发展,并给我们带来了进一步探究的可能性。 一般地,表示学习的研究可以按照不同角度进行划分:从学习方式上,可以分为有监督学习和无监督学习;从输入数据模态上,可以分为文本表示、图像表示以及语音表示;从共享独立性上,可以分为共享表示和私有表示。 在自然语言处理中,使用深度学习技术(即深度神经网络)对文本进行表示学习已经成为一个很有价值的研究方向。本文工作围绕着以下问题展开: 1)\textbf{对于不同粒度的文本(词语、句子、句对),如何设计合理的结构,使得模型可以学习到适合最终任务的表示?} 深度学习的到来使得自然语言处理中的研究工作由原来的\textit{特征工程} (feature engineering) 过渡到了现在的\textit{结构工程} (architecture engineering) ,而对于文本的表示学习,首先要解决的最基本问题就是寻找合适的\textit{归纳偏置}(inductive bias),使得模型可以更好地对输入文本进行编码。 而本文分别针对不同粒度的文本信号,进行相应的网络结构探索,希望找到更适合下游任务的结构偏置。 2)\textbf{如何进行针对性的迁移学习?} 有针对性地进行迁移是指我们要对迁移的知识“按需分配”,这就要求我们学习的知识应该具备\textit{可迁移性},此外,我们还要对已有的知识进行\textit{可理解分析},从而可以\textit{分离}我们真正需要的知识,最终实现知识的定向迁移。 对于以上两个亟待解决的问题,本文通过两个方面,九个章节进行递进式探讨。
Paper
Related Datasets (Coming soon)